.png)


Our collaboration has been instrumental in advancing critical aspects of our projects. From significantly enhancing model evaluations through thorough cleanup efforts and intelligent error recovery, to swiftly generating crucial RLHF data that rectified model behaviors, we've achieved substantial improvements.”

Expand model capabilities with expert data packs
Get data built for post-training improvement, not just evaluation. From SWE-Bench-style issue sets to multimodal UI gyms, our data teaches your model to reason, use tools, and adapt across domains.
Frontier post-training data across coding, STEM, and more
Data packs combine curated tasks, taxonomies, and validator review with full lineage for integration. Choose from established domains, or request a custom pack for new workflows or research goals.

Coding
Reasoning traces, coding agents, and repo tasks modeled on SWE-Bench for real-world evaluation.

STEM
Math, physics, chemistry, and biology datasets with calibrated ambiguity and domain-expert validation.
Domain-Specific
Finance, economics, legal, and medical reasoning data with attribution-first rubrics and QA.

Multimodality
Audio, image, video, GUI, and self-driving datasets built for multimodal reasoning and tool use.

Robotics (Early Access)
World modeling, embodied chain-of-thought, and simulation-driven trajectories for robotics and control.

Custom
Don’t see what you need? Request bespoke packs across new domains, workflows, or modalities.
Built for reproducibility and improvement
Structured generation and verification beyond simple annotation or static evaluations.
1
Frontier evaluators
PhDs, Olympiad medalists, and FAANG-level engineers calibrate ambiguity before scale
2
Traceable lineage
evaluator→validator review with auditable provenance at every step
3
Benchmarks & environments
SWE-Bench, VLM-Bench, HLE, and RL gyms across domains
4
Flexible formats
delivered for SFT, DPO/RLHF, evals, and RL
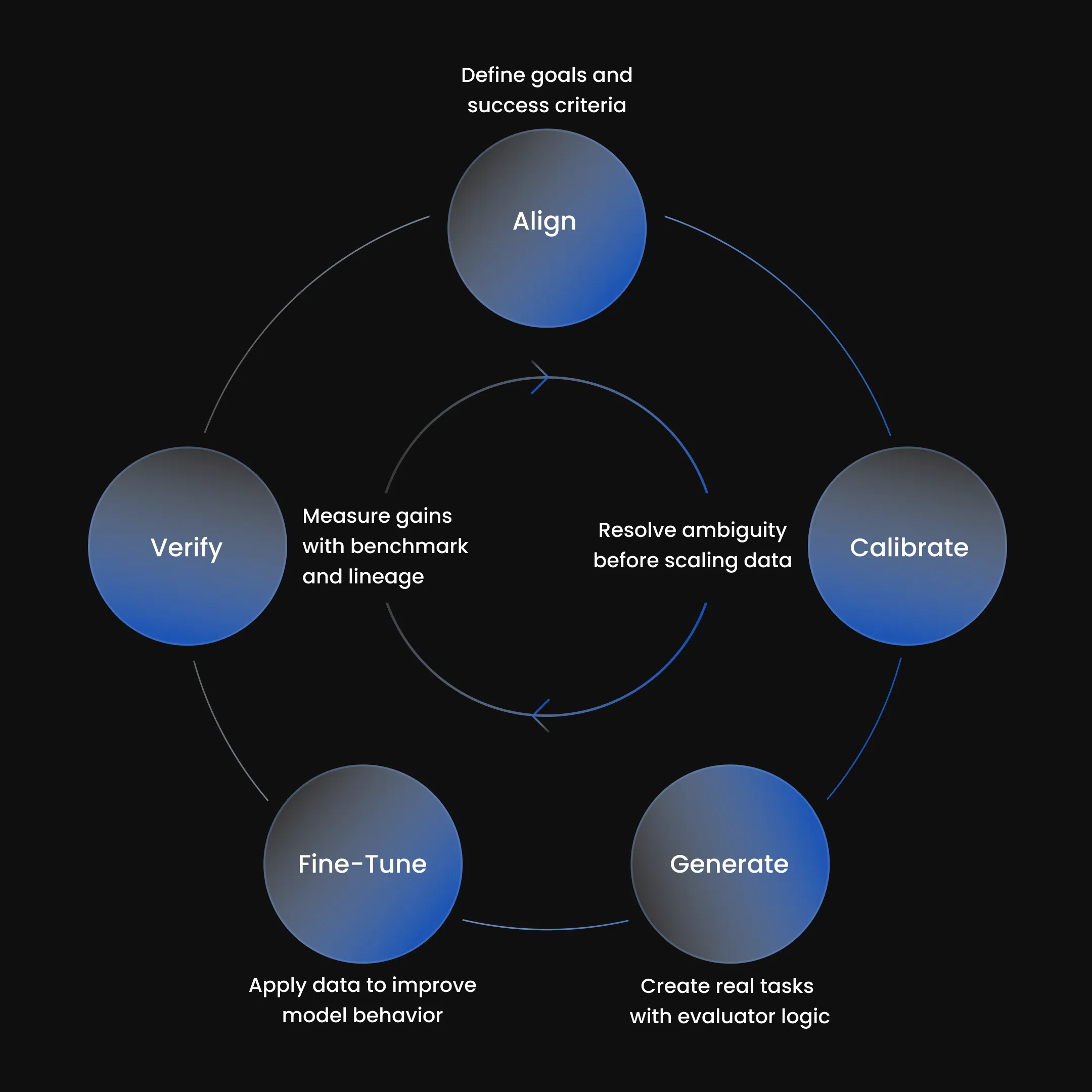
Our Five-Step Framework
This is some text inside of a div block.
Evaluation tools across the model lifecycle
Public and private benchmarks, and agentic environments, help identify failure points, verify improvements, and validate model alignment, across every post-training stage.
- Coding: SWE-Bench, SWE-Bench-Verified, SWE-Lancer lineage
- Multimodality: VLM-Bench, chart/table/diagram reasoning tasks
- Reasoning: Humanity’s Last Exam (HLE) hillclimbs
- Agentic workflows: RL gyms for GUI, tool use, and function-calling environments
Featured Resources
This is some text inside of a div block.
Research and results you can build on
Explore the research anchors and resources that shape our data pack design.
.png)
Senior Staff Software Engineer
Research Head leading Implicit Code Execution
@ Gemini

