
Structure the next generation of model reasoning
Build, test, and refine model behavior in real-world environments. From reinforcement learning and code reasoning to scalable evaluation systems, and robust data packs, Turing structures what happens after training.








RL environments for agent evaluation
Turing RL environments replicate consumer and enterprise systems in detail: browser-use, workflow automation, and backend function-calling.
Each environment is packaged as a Docker container with APIs for task retrieval, environment resets, and verifier-based scoring, enabling structured experimentation at scale
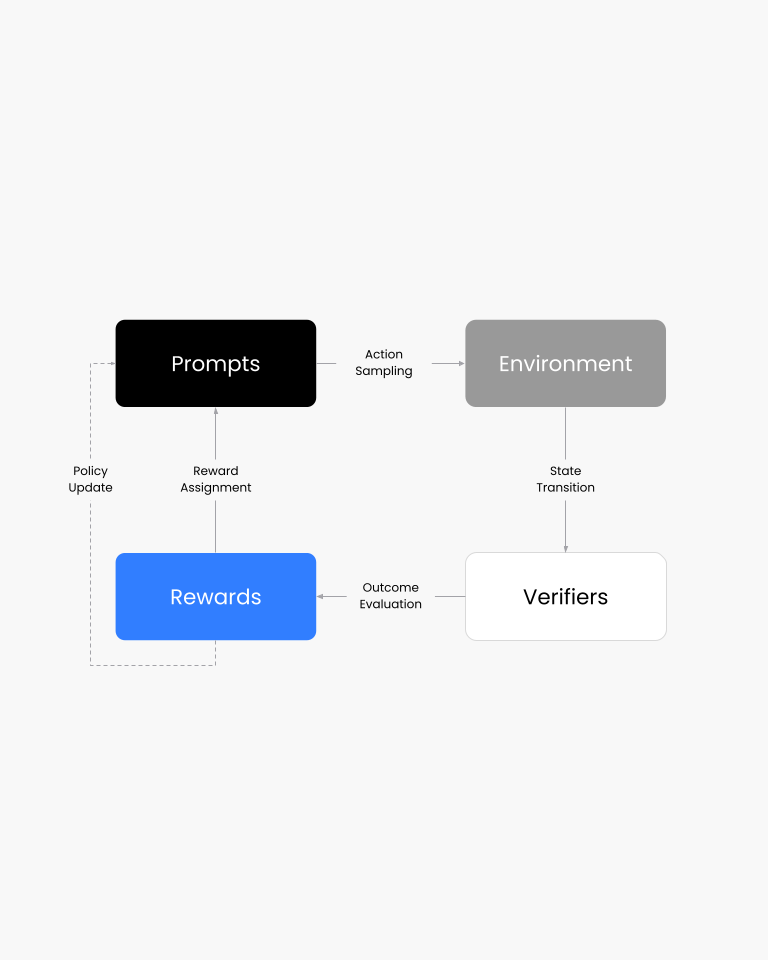
Turing’s UI RL environments simulate authentic enterprise and consumer systems where agents must plan, adapt, and recover through real UI interactions. Every element from click paths, state transitions, and verifier logic, is designed to turn browser behavior into a structured reasoning challenge.
What sets Turing apart is depth and fidelity: each environment mirrors live software workflows with deterministic verifiers and measurable reward signals, exposing not just what agents can do, but how they reason when confronted with uncertainty.
Turing’s MCP environments test reasoning in the invisible layer - where function calls, APIs, and decision logic define performance. These environments recreate enterprise workflows through structured tool calls and state-tracked verifiers that make reasoning measurable.
By combining deterministic evaluation, multi-agent reinforcement, and domain-specific logic packs, MCP environments reveal how agents learn to compose, critique, and refine decisions—the foundation of real-world reasoning maturity.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec pharetra sem vitae viverra iaculis. Donec pretium a justo eget eleifend. Praesent eu nunc id diam vehicula accumsan a eu justo. Sed ut dolor in nisl finibus accumsan.
Reliable systems for code reasoning
Turing’s coding ecosystem provides structured benchmarks, curated datasets, and repeatable evaluation systems that measure how well models reason, debug, and generate production-grade code.
Our data enables benchmarking, fine-tuning, and reinforcement across multi-language and multi-domain coding tasks.
Deploy → Observe failures → Convert failures into better data → Improve models → Redeploy.
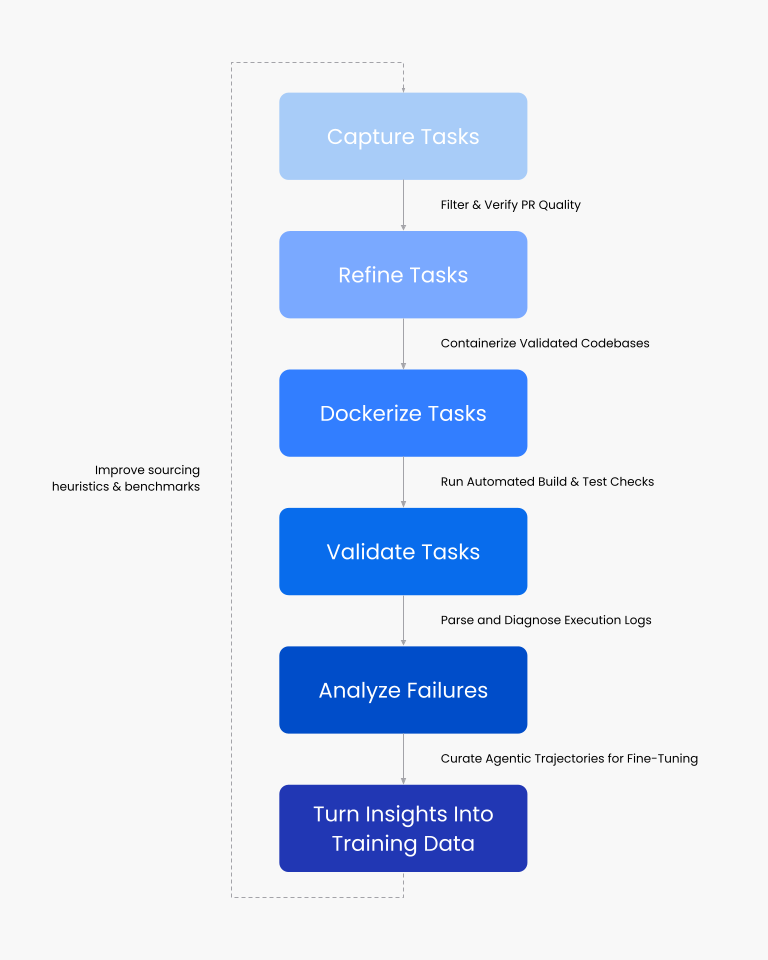



Core Capabilities
Dynamic reasoning benchmark built on verified GitHub issues and containerized environments for auditable code reasoning.
Private dataset of 900+ multilingual coding challenges with deterministic scoring for bias-free evaluation.
Structured IaC datasets mirroring real-world cloud deployments for DevOps and automation reasoning.
Evaluate agentic logic across APIs, tools, and custom functions, ensuring alignment between intent and execution.
Structured hill-climb analysis converts unstructured outputs into actionable traces for reproducible fine-tuning.
All datasets and benchmarks map to Turing’s Five-Step Framework, reinforcing repeatability and QA consistency.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec pharetra sem vitae viverra iaculis. Donec pretium a justo eget eleifend. Praesent eu nunc id diam vehicula accumsan a eu justo. Sed ut dolor in nisl finibus accumsan.
Closing the Gap Between Model Potential and Production Reality
Turing brings real-world environments, production-grade benchmarks to scale with the evaluation and systems advanced models need. This is where intelligence stops being a lab result and starts becoming economic output.
Why Turing?
The next winners won’t be defined by demos or benchmarks. They’ll be defined by execution: shipping into production, learning where systems break, and compounding those learnings into infrastructure.


